With all the hardware working from Part 1, it’s time to move onto getting all the software in place. There were plenty of references to work from, and based the on the recommendations of Wireless Village to bring Pentoo Linux for the WCTF, that’s where I started. Here are some lists that I worked from:
This is where I started just going through the list of packages and tried a dnf install. Many of these are standard Linux packages installed by default, a lot of them are also included as part of the base Fedora distribution. But, there are several that needs supplemental repo’s added to the dnf package system to make install (and upgrades/maintenance later) easier. I didn’t install everything, but I tried to make sure I covered many of the big ones, as well as some others I had seen in tutorials. As I get more time with the laptop, and other CTF/WCTF, I’ll be able to fine tune the install.
Supplemental Software Repositories
The following are the collection of external repos I’ve added to the base distribution to support the additional tools needed.
Fedora 27 openh264 (From Cisco)
This is really about just enabling the repo which is installed by default but disabled. Some CTF may have audio coding/decoding requirements and this adds to your options.
sudo dnf config-manager --set-enabled fedora-cisco-openh264
RPM Fusion for Fedora 27 – Free
RPM Fusion provides a large collection of additional packages from several sources that the core Fedora team does not wish to provide in core Fedora. It will also provide a lot of dependencies for packages from other repos. Updates are not as guaranteed as the core Fedora repo, but most packagers are pretty good at keep them up2date.
The Free repo covers fully open-sourced packages that Fedora was unable to make part of the base distro for various reasons.
sudo dnf install https://download1.rpmfusion.org/free/fedora/rpmfusion-free-release-$(rpm -E %fedora).noarch.rpm
RPM Fusion for Fedora 27 – Nonfree
These are restrictive open-source or not-for-commercial use licensed packages. If this is for personal use you should be fine, but if you mix work with pleasure, be warned, check the individual packages licenses before use.
sudo dnf install https://download1.rpmfusion.org/nonfree/fedora/rpmfusion-nonfree-release-$(rpm -E %fedora).noarch.rpm
CERT Forensics Tools Repository
Linux Forensics Tools Repository – LiFTeR is a gold mine for CTF based tools for forensics and similar operations. You will want rpmfusion installed to help support some of these packages.
First I suggest adding the CERT gpg key to dnf to verify packages:
sudo rpm --import https://forensics.cert.org/forensics.asc
Then you can install the repo rpm.
sudo dnf install https://forensics.cert.org/cert-forensics-tools-release-27.rpm
Atomic Corp Repo
Atomic corp are the backers of OSSEC OpenSource HIDs solution, but they have a collection of security tools to supplement the above repos. Tools like dirb.
sudo rpm -ivh http://www6.atomicorp.com/channels/atomic/fedora/27/x86_64/RPMS/atomic-release-1.0-21.fc27.art.noarch.rpm
Metasploit
It goes with out saying you’ll want to have Metasploit at your disposal, it’s a foundation tool that will help in your early offensive operations. There are two versions that Rapid7 provides: the free Open Source Metasploit Framework and the paid Commercial Support Metasploit Pro. The following instructions are for the free Open Source version, it will suffice to get you started, and provides opportunities to learn.
Unfortunately the install process is not a clean dnf focused procedure, they supply an install script that hides some of the complexity, but I choose to figure out how to get it working with out their install script and just add it to my dnf repo collection. Again rpmfusion above will help with dependencies.
First thing is we need to get the Rapid7 GPG key. That can be found in their installer script at the top here.
curl https://raw.githubusercontent.com/rapid7/metasploit-omnibus/master/config/templates/metasploit-framework-wrappers/msfupdate.erb 2>/dev/null | sed -e '1,/EOF/d' -e '/EOF/,$d' > metasploit.asc
We then need to add it to our rpm key signing store:
rpm --import metasploit.asc
Now we can manually add the Metasploit nightly rpm repo to dnf, and rpm install signatures should be happily verified going forward.
sudo dnf config-manager --add-repo https://rpm.metasploit.com/
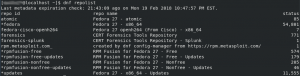
You can run the following command to confirm the repos are installed and ready to go (you may be accessed to accept several Fedora GPG keys being imported from the local installs)
dnf repolist
You should see something like this:
Packages Installed
With all the above in place there are two obvious installs you’ll want to do. The full LiFTeR suite of tools and MetaSploit (warning this is about 3GB of software about to be installed, it’s a LOT of tools):
sudo dnf install CERT-Forensics-Tools metasploit-framework
Besides Metasploit (Exploitation/Pen-testing tool) your going to get Autoposy/SleuthKit (Forensics tool kit), Volatility (Memory Forensics), Silk (Packet analysis suite), Snort (IPS and packet analysis), nmap (Network Mapping and recon), Wireshark (Packet Analysis), and a huge host of other tools and supporting libraries.
Next up are a collection of individual tools that are also included in Pentoo, but the above did not install.
First up is a collection of assorted tools that deal with a range of WCTF/CTF exercises including password cracking, binary/code analysis, network analysis, network recon, exploit development, and more provided by Fedora.
sudo dnf install aircrack-ng scapy masscan zmap kismet kismet-plugins kismon gdb strace nacl-binutils nacl-arm-binutils examiner upx pcsc-lite-ccid chntpw libykneomgr libu2f-host mhash ophcrack chntpw libykneomgr libu2f-host mhash john ophcrack xorsearch crack sucrack ncrack ophcrack aircrack-ng pdfcrack cowpatty hydra medusa airsnort weplab tor flawfinder sage reaver urh hackrf hackrf-static cracklib-python perl-Crypt-Cracklib nikto dirb unicornscan net-snmp net-snmp-utils net-snmp-python net-snmp-perl net-snmp-gui skipfish
The following are more standard Linux tools, but very helpful in WCTF/CTF to handle audio/video analysis/manipulation, picture analysis/manipulation, coding, and quick network controls.
sudo dnf install vim-enhanced gstreamer1-plugin-openh264 mozilla-openh264 vlc python-vlc npapi-vlc dkms audacity ffmpeg firewall-applet system-config-firewall gimp nasm
Software Manually Installed
There were three packages I wanted to work with, but could not find good pre-built rpms of: hashcat, SANS SIFT
SANS SIFT
This can be gotten via VM, ISO, or installed locally. In truth, it duplicates a lot of the tools already installed above. I started down this route, then realized I would probably want to stick to the previous rpm route. You can find the different install instructions here.
hashcat
This is a classic password cracker that supports a world of different CPU/GPU acceleration options. I’m somewhat limited given I’m running this on a laptop, but still an important tool to have at hand. Need to link it into some cloud based compute resources…
For install, it’s the classic download, verify, copy.
First lets make an area to handle non-normal apps (feel free to change this to your liking).
cd ~; mkdir Apps; cd Apps
Then retrieve the hashcat public key
gpg --keyserver keyserver.ubuntu.com --recv 8A16544F
Next download their pgp signing key
curl --output hashcat-4.0.1.7z.asc https://hashcat.net/files/hashcat-4.0.1.7z.asc
Then download their binary
curl --output hashcat-4.0.1.7z https://hashcat.net/files/hashcat-4.0.1.7z
Then verify signature
gpg --verify hashcat-4.0.1.7z.asc hashcat-4.0.1.7z
Then we can expand it and then install it.
7za x hashcat-4.0.1.7z
cd hashcat-4.0.1/
sudo cp hashcat64.bin /usr/local/bin/hashcat
And now it’s ready and in our path. Downside is that we have to remember to manually check for updates occasionally.
Now onto WEP/WPA2 Cracking!
In part 3 of course. Yeah, I know, it’s a tease, but want to get this software install bit out there, while I write up what I learned about WEP/WPA2 hacking. I’ll cover basics like packet captures, packet injections (to force handshakes), and brute force pass-phrase recovery.